窗口函数
Goose 支持窗口函数,它可以使用多行数据为每一行计算一个值。 窗口函数属于阻塞算子,即需要先缓冲全部输入,因此是 SQL 中最耗内存的算子之一。
窗口函数从 SQL:2003 起已纳入 SQL 标准,并被主流 SQL 数据库系统支持。
示例
生成一个 row_number 列来为行编号:
SELECT row_number() OVER ()
FROM sales;
提示 如果你只需要为表中每一行生成一个编号,可以使用
rowid伪列。
生成一个 row_number 列来为行编号,并按 time 排序:
SELECT row_number() OVER (ORDER BY time)
FROM sales;
生成一个 row_number 列来为行编号,并按 time 排序、按 region 分区:
SELECT row_number() OVER (PARTITION BY region ORDER BY time)
FROM sales;
计算当前 amount 与按 time 排序的上一行 amount 之间的差值:
SELECT amount - lag(amount) OVER (ORDER BY time)
FROM sales;
计算每行在其 region 分区内 amount 总和中的占比:
SELECT amount / sum(amount) OVER (PARTITION BY region)
FROM sales;
语法
窗口函数只能在 SELECT 子句中使用。若要在多个函数之间复用 OVER 规范,请使用语句的
WINDOW 子句,并采用 OVER ⟨window_name⟩ 语法。
通用窗口函数
下表展示可用的通用窗口函数。
| 名称 | 说明 |
|---|---|
cume_dist([ORDER BY ordering]) | 累积分布:(位于当前行之前或与当前行并列的分区行数) / 分区总行数。 |
dense_rank() | 当前行的排名(无空缺);该函数按并列组计数。 |
fill(expr [ ORDER BY ordering]) | 使用线性插值补齐缺失值,ORDER BY 作为 X 轴。 |
first_value(expr[ ORDER BY ordering][ IGNORE NULLS]) | 返回窗口框架中首行(若设置 IGNORE NULLS 则为 expr 非空的首行)上的 expr 值。 |
lag(expr[, offset[, default]][ ORDER BY ordering][ IGNORE NULLS]) | 返回窗口框架内当前行之前第 offset 行(若设置 IGNORE NULLS 则仅在 expr 非空行中计数)的 expr 值;若不存在该行,返回 default(类型必须与 expr 相同)。offset 和 default 都相对于当前行求值。省略时,offset 默认为 1,default 默认为 NULL。 |
last_value(expr[ ORDER BY ordering][ IGNORE NULLS]) | 返回窗口框架中末行(若设置 IGNORE NULLS 则为 expr 非空的末行)上的 expr 值。 |
lead(expr[, offset[, default]][ ORDER BY ordering][ IGNORE NULLS]) | 返回窗口框架内当前行之后第 offset 行(若设置 IGNORE NULLS 则仅在 expr 非空行中计数)的 expr 值;若不存在该行,返回 default(类型必须与 expr 相同)。offset 和 default 都相对于当前行求值。省略时,offset 默认为 1,default 默认为 NULL。 |
nth_value(expr, nth[ ORDER BY ordering][ IGNORE NULLS]) | 返回窗口框架中第 nth 行(从 1 开始计数;若设置 IGNORE NULLS 则仅在 expr 非空行中计数)的 expr 值;若不存在该行,则返回 NULL。 |
ntile(num_buckets[ ORDER BY ordering]) | 返回 1 到 num_buckets 之间的整数,尽可能均匀地划分分区。 |
percent_rank([ORDER BY ordering]) | 当前行的相对排名:(rank() - 1) / (total partition rows - 1)。 |
rank([ORDER BY ordering]) | 当前行的排名(有空缺);等同于其首个并列行的 row_number。 |
row_number([ORDER BY ordering]) | 当前行在分区内的行号,从 1 开始。 |
cume_dist([ORDER BY ordering])
| 说明 | 累积分布:(位于当前行之前或与当前行并列的分区行数) / 分区总行数。若指定 ORDER BY 子句,则在框架内按提供的排序(而非框架排序)计算分布。 |
| 返回类型 | DOUBLE |
| 示例 | cume_dist() |
dense_rank()
| 说明 | 当前行的排名(无空缺);该函数按并列组计数。 |
| 返回类型 | BIGINT |
| 示例 | dense_rank() |
| 别名 | rank_dense() |
fill(expr[ ORDER BY ordering])
| 说明 | 使用最接近的非 NULL 值及其排序值,对 expr 的 NULL 值进行线性插值。两者都必须支持算术运算,且只能有一个排序键。对于两端缺失值,使用线性外推。若无法插值,则保留 NULL。 |
| 返回类型 | 与 expr 相同 |
| 示例 | fill(column) |
first_value(expr[ ORDER BY ordering][ IGNORE NULLS])
| 说明 | 返回窗口框架中首行(若设置 IGNORE NULLS 则为 expr 非空的首行)上的 expr 值。若指定 ORDER BY 子句,则在框架内按提供的排序(而非框架排序)确定首行。 |
| 返回类型 | 与 expr 相同 |
| 示例 | first_value(column) |
lag(expr[, offset[, default]][ ORDER BY ordering][ IGNORE NULLS])
| 说明 | 返回窗口框架内当前行之前第 offset 行(若设置 IGNORE NULLS 则仅在 expr 非空行中计数)的 expr 值;若不存在该行,返回 default(类型必须与 expr 相同)。offset 和 default 都相对于当前行求值。省略时,offset 默认为 1,default 默认为 NULL。若指定 ORDER BY 子句,则在框架内按提供的排序(而非框架排序)计算滞后行号。 |
| 返回类型 | 与 expr 相同 |
| 示例 | lag(column, 3, 0) |
last_value(expr[ ORDER BY ordering][ IGNORE NULLS])
| 说明 | 返回窗口框架中末行(若设置 IGNORE NULLS 则为 expr 非空的末行)上的 expr 值。若指定 ORDER BY 子句,则在框架内按提供的排序(而非框架排序)确定末行。 |
| 返回类型 | 与 expr 相同 |
| 示例 | last_value(column) |
lead(expr[, offset[, default]][ ORDER BY ordering][ IGNORE NULLS])
| 说明 | 返回窗口框架内当前行之后第 offset 行(若设置 IGNORE NULLS 则仅在 expr 非空行中计数)的 expr 值;若不存在该行,返回 default(类型必须与 expr 相同)。offset 和 default 都相对于当前行求值。省略时,offset 默认为 1,default 默认为 NULL。若指定 ORDER BY 子句,则在框架内按提供的排序(而非框架排序)计算超前行号。 |
| 返回类型 | 与 expr 相同 |
| 示例 | lead(column, 3, 0) |
nth_value(expr, nth[ ORDER BY ordering][ IGNORE NULLS])
| 说明 | 返回窗口框架中第 nth 行(从 1 开始计数;若设置 IGNORE NULLS 则仅在 expr 非空行中计数)的 expr 值;若不存在该行则返回 NULL。若指定 ORDER BY 子句,则在框架内按提供的排序(而非框架排序)计算第 nth 行。 |
| 返回类型 | 与 expr 相同 |
| 示例 | nth_value(column, 2) |
ntile(num_buckets[ ORDER BY ordering])
| 说明 | 返回 1 到 num_buckets 之间的整数,尽可能均匀地划分分区。若指定 ORDER BY 子句,则在框架内按提供的排序(而非框架排序)计算 ntile。 |
| 返回类型 | BIGINT |
| 示例 | ntile(4) |
percent_rank([ORDER BY ordering])
| 说明 | 当前行的相对排名:(rank() - 1) / (total partition rows - 1)。若指定 ORDER BY 子句,则在框架内按提供的排序(而非框架排序)计算相对排名。 |
| 返回类型 | DOUBLE |
| 示例 | percent_rank() |
rank([ORDER BY ordering])
| 说明 | 当前行的排名(有空缺);等同于其首个并列行的 row_number。若指定 ORDER BY 子句,则在框架内按提供的排序(而非框架排序)计算排名。 |
| 返回类型 | BIGINT |
| 示例 | rank() |
row_number([ORDER BY ordering])
| 说明 | 当前行在分区内的行号,从 1 开始。若指定 ORDER BY 子句,则在框架内按提供的排序(而非框架排序)计算行号。 |
| 返回类型 | BIGINT |
| 示例 | row_number() |
聚合窗口函数
所有聚合函数都可以在窗口上下文中使用,包括可选的 FILTER 子句。
first 和 last 聚合函数会被对应的通用窗口函数遮蔽;因此这些函数不支持 FILTER 子句,但支持 IGNORE NULLS。
DISTINCT 参数
所有聚合窗口函数都支持在参数上使用 DISTINCT 子句。提供 DISTINCT 子句后,聚合计算只考虑去重后的值。它通常与 COUNT 聚合结合使用以计算不同元素的数量;但也可与系统中的任意聚合函数一起使用。有些聚合对重复值不敏感(如 min、max),对它们而言该子句会被解析但忽略。
-- Count the number of distinct users at a given point in time
SELECT count(DISTINCT name) OVER (ORDER BY time) FROM sales;
-- Concatenate those distinct users into a list
SELECT list(DISTINCT name) OVER (ORDER BY time) FROM sales;
ORDER BY 参数
所有聚合窗口函数都支持使用与窗口排序不同的 ORDER BY 参数子句。提供该子句后,会先对参与聚合的值排序,再应用函数。通常这不重要,但某些对顺序敏感的聚合(如 mode、list 和 string_agg)可能产生不确定结果。通过对参数排序可以让它们变得确定。对于对顺序不敏感的聚合,该子句会被解析但忽略。
-- Compute the modal value up to each time, breaking ties in favor of the most recent value.
SELECT mode(value ORDER BY time DESC) OVER (ORDER BY time) FROM sales;
SQL 标准并未规定通用窗口函数可使用 ORDER BY 参数,但我们已扩展这些函数(dense_rank 除外)以支持该语法,并使用 framing 限制该次级排序生效的范围。
-- Compare each athlete's time in an event with the best time to date
SELECT event, date, athlete, time
first_value(time ORDER BY time DESC) OVER w AS record_time,
first_value(athlete ORDER BY time DESC) OVER w AS record_athlete,
FROM meet_results
WINDOW w AS (PARTITION BY event ORDER BY datetime)
ORDER BY ALL
注意:参数与 ORDER BY 子句之间不使用逗号分隔。
Null 值
所有支持 IGNORE NULLS 的通用窗口函数默认都采用 respect nulls 的行为。该默认行为也可显式写为 RESPECT NULLS。
相对地,所有聚合窗口函数(list 及其别名除外,它们可通过 FILTER 忽略 null)都会忽略 null,且不接受 RESPECT NULLS。例如,sum(column) OVER (ORDER BY time) AS cumulativeColumn 会计算累积和;当某行 column 为 NULL 时,该行 cumulativeColumn 与前一行相同。
求值过程
窗口计算的工作方式是:先把关系拆分为相互独立的 partitions,再对每个分区进行 ordering,然后基于邻近值为每行计算一个新列。 某些窗口函数只依赖分区边界与排序,但也有一些(包括所有聚合函数)还会使用 frame。 frame 以 current row 为中心,指定其前后(preceding 或 following)的行范围。 距离可以表示为 rows 数量、基于分区排序值与距离的 range,或 groups 数量(排序值相同的行集合)。
完整语法见页面顶部图示,该图也直观展示了计算环境:
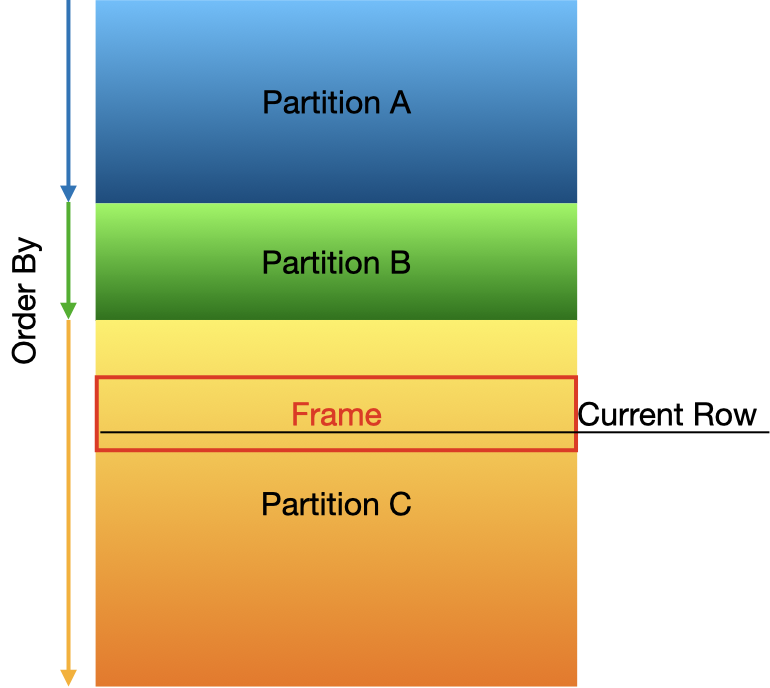
分区与排序
分区会将关系拆分为彼此独立、互不相关的部分。 分区是可选的;若未指定,则整个关系被视为一个分区。 窗口函数无法访问当前行所在分区之外的值。
排序同样是可选的,但若没有排序,通用窗口函数、顺序敏感聚合函数以及 framing 的顺序都没有明确定义。 每个分区都使用同一个排序子句进行排序。
这里是一张发电数据表,可作为 CSV 文件获取(power-plant-generation-history.csv)。加载数据可运行:
CREATE TABLE "Generation History" AS
FROM 'power-plant-generation-history.csv';
按电厂分区并按日期排序后,布局如下:
| Plant | Date | MWh |
|---|---|---|
| Boston | 2019-01-02 | 564337 |
| Boston | 2019-01-03 | 507405 |
| Boston | 2019-01-04 | 528523 |
| Boston | 2019-01-05 | 469538 |
| Boston | 2019-01-06 | 474163 |
| Boston | 2019-01-07 | 507213 |
| Boston | 2019-01-08 | 613040 |
| Boston | 2019-01-09 | 582588 |
| Boston | 2019-01-10 | 499506 |
| Boston | 2019-01-11 | 482014 |
| Boston | 2019-01-12 | 486134 |
| Boston | 2019-01-13 | 531518 |
| Worcester | 2019-01-02 | 118860 |
| Worcester | 2019-01-03 | 101977 |
| Worcester | 2019-01-04 | 106054 |
| Worcester | 2019-01-05 | 92182 |
| Worcester | 2019-01-06 | 94492 |
| Worcester | 2019-01-07 | 99932 |
| Worcester | 2019-01-08 | 118854 |
| Worcester | 2019-01-09 | 113506 |
| Worcester | 2019-01-10 | 96644 |
| Worcester | 2019-01-11 | 93806 |
| Worcester | 2019-01-12 | 98963 |
| Worcester | 2019-01-13 | 107170 |
在下文中,我们将使用这张表(或其中片段)来说明窗口函数求值的各个部分。
最简单的窗口函数是 row_number()。
该函数只需通过如下查询计算分区内从 1 开始的行号:
SELECT
"Plant",
"Date",
row_number() OVER (PARTITION BY "Plant" ORDER BY "Date") AS "Row"
FROM "Generation History"
ORDER BY 1, 2;
结果如下:
| Plant | Date | Row |
|---|---|---|
| Boston | 2019-01-02 | 1 |
| Boston | 2019-01-03 | 2 |
| Boston | 2019-01-04 | 3 |
| ... | ... | ... |
| Worcester | 2019-01-02 | 1 |
| Worcester | 2019-01-03 | 2 |
| Worcester | 2019-01-04 | 3 |
| ... | ... | ... |
注意,即便函数计算时使用了 ORDER BY 子句,结果本身也不一定有序;如果需要有序输出,仍需在 SELECT 中显式排序。
Framing
Framing 定义了函数在每一行求值时所参考的相对行集合。
与当前行的距离可表示为在 OVER 规范中由 ORDER BY 定义顺序下,相对当前行的 PRECEDING 或 FOLLOWING 表达式。
该距离可指定为 ROWS 或 GROUPS 的整数数量,也可指定为 RANGE 的差值表达式。frame 起点晚于终点是非法的。
对于 RANGE 规范,必须只有一个排序表达式,且该表达式必须支持减法;除非仅使用边界哨兵值 UNBOUNDED PRECEDING / UNBOUNDED FOLLOWING / CURRENT ROW。
可通过 EXCLUDE 子句 将在指定排序表达式上与当前行相等的行(即 peers)从 frame 中排除。
默认 frame 在无 ORDER BY 子句时是 unbounded(即整个分区);在有 ORDER BY 子句时是 RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW。默认情况下,CURRENT ROW 边界值(不包括 EXCLUDE 子句中的 CURRENT ROW)在使用 RANGE 或 GROUP framing 时表示当前行及其所有 peers,而在 ROWS framing 时仅表示当前行。
ROWS Framing
下面是一个使用聚合函数的简单 ROW frame 查询:
SELECT points,
sum(points) OVER (
ROWS BETWEEN 1 PRECEDING
AND 1 FOLLOWING) AS we
FROM results;
该查询会计算每个点及其左右相邻点的 sum:
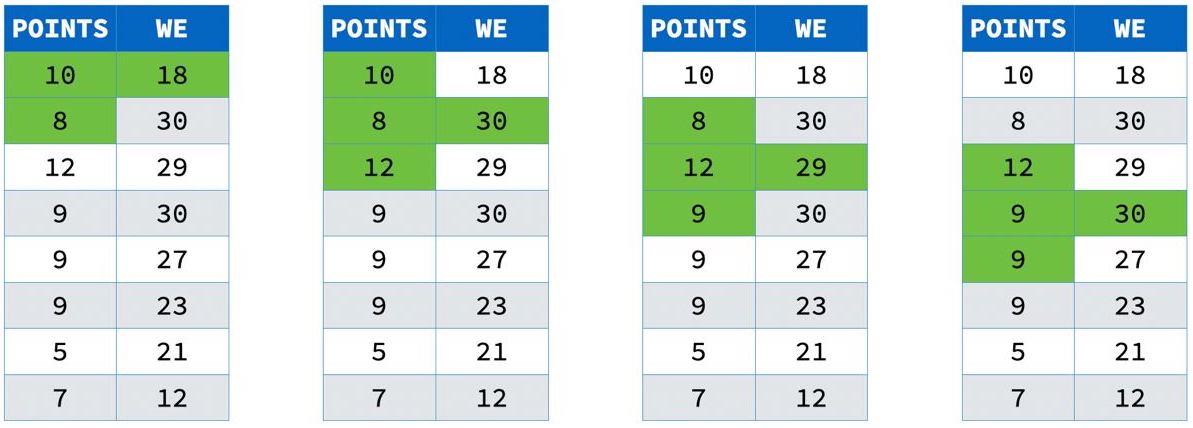
注意在分区边界处只会相加两个值。 这是因为 frame 会被裁剪到分区边界。
RANGE Framing
回到发电数据,假设数据有噪声。 我们可能希望为每个电厂计算 7 天移动平均以平滑噪声。 可以使用如下窗口查询:
SELECT "Plant", "Date",
avg("MWh") OVER (
PARTITION BY "Plant"
ORDER BY "Date" ASC
RANGE BETWEEN INTERVAL 3 DAYS PRECEDING
AND INTERVAL 3 DAYS FOLLOWING)
AS "MWh 7-day Moving Average"
FROM "Generation History"
ORDER BY 1, 2;
该查询按 Plant 对数据分区(保持不同电厂数据独立),
按 Date 对每个电厂分区排序(让时间上相邻的能量读数排在一起),
并为 avg 使用前后各三天的 RANGE frame(以处理缺失日期)。
结果如下:
| Plant | Date | MWh 7-day Moving Average |
|---|---|---|
| Boston | 2019-01-02 | 517450.75 |
| Boston | 2019-01-03 | 508793.20 |
| Boston | 2019-01-04 | 508529.83 |
| ... | ... | ... |
| Boston | 2019-01-13 | 499793.00 |
| Worcester | 2019-01-02 | 104768.25 |
| Worcester | 2019-01-03 | 102713.00 |
| Worcester | 2019-01-04 | 102249.50 |
| ... | ... | ... |
GROUPS Framing
第三种 framing 是按相对当前行的 groups 计数。
这里的 group 指 ORDER BY 值相同的一组行。
若假设每天都有发电,
我们可以使用 GROUPS framing 计算系统总发电量的移动平均,
无需进行日期算术:
SELECT "Date", "Plant",
avg("MWh") OVER (
ORDER BY "Date" ASC
GROUPS BETWEEN 3 PRECEDING
AND 3 FOLLOWING)
AS "MWh 7-day Moving Average"
FROM "Generation History"
ORDER BY 1, 2;
| Date | Plant | MWh 7-day Moving Average |
|---|---|---|
| 2019-01-02 | Boston | 311109.500 |
| 2019-01-02 | Worcester | 311109.500 |
| 2019-01-03 | Boston | 305753.100 |
| 2019-01-03 | Worcester | 305753.100 |
| 2019-01-04 | Boston | 305389.667 |
| 2019-01-04 | Worcester | 305389.667 |
| ... | ... | ... |
| 2019-01-12 | Boston | 309184.900 |
| 2019-01-12 | Worcester | 309184.900 |
| 2019-01-13 | Boston | 299469.375 |
| 2019-01-13 | Worcester | 299469.375 |
注意每个日期对应的值都相同。
EXCLUDE 子句
EXCLUDE 是 frame 子句的可选修饰符,用于排除 CURRENT ROW 周围的行。
当你想计算邻近行的某个聚合值,并据此比较当前行时,这很有用。
在下面示例中,我们希望比较某运动员在某项目中的成绩与该项目 ±10 天内所有记录成绩的平均值:
SELECT
event,
date,
athlete,
avg(time) OVER w AS recent,
FROM results
WINDOW w AS (
PARTITION BY event
ORDER BY date
RANGE BETWEEN INTERVAL 10 DAYS PRECEDING AND INTERVAL 10 DAYS FOLLOWING
EXCLUDE CURRENT ROW
)
ORDER BY event, date, athlete;
EXCLUDE 有四种选项,用于指定如何处理当前行:
CURRENT ROW– 仅排除当前行GROUP– 排除当前行及其所有“peer”(ORDER BY值相同的行)TIES– 排除所有 peer 行,但不排除当前行(会在两侧形成空洞)NO OTHERS– 不排除任何行(默认)
排除机制既适用于窗口聚合,也适用于 first、last 和 nth_value 函数。
WINDOW 子句
在同一个 SELECT 中可以指定多个不同的 OVER 子句,并分别计算。
但很多时候我们希望多个窗口函数复用同一种布局。
WINDOW 子句可定义一个可复用的命名窗口,供多个窗口函数共享:
SELECT "Plant", "Date",
min("MWh") OVER seven AS "MWh 7-day Moving Minimum",
avg("MWh") OVER seven AS "MWh 7-day Moving Average",
max("MWh") OVER seven AS "MWh 7-day Moving Maximum"
FROM "Generation History"
WINDOW seven AS (
PARTITION BY "Plant"
ORDER BY "Date" ASC
RANGE BETWEEN INTERVAL 3 DAYS PRECEDING
AND INTERVAL 3 DAYS FOLLOWING)
ORDER BY 1, 2;
这三个窗口函数还会共享数据布局,从而提升性能。
可在同一个 WINDOW 子句中用逗号分隔定义多个窗口:
SELECT "Plant", "Date",
min("MWh") OVER seven AS "MWh 7-day Moving Minimum",
avg("MWh") OVER seven AS "MWh 7-day Moving Average",
max("MWh") OVER seven AS "MWh 7-day Moving Maximum",
min("MWh") OVER three AS "MWh 3-day Moving Minimum",
avg("MWh") OVER three AS "MWh 3-day Moving Average",
max("MWh") OVER three AS "MWh 3-day Moving Maximum"
FROM "Generation History"
WINDOW
seven AS (
PARTITION BY "Plant"
ORDER BY "Date" ASC
RANGE BETWEEN INTERVAL 3 DAYS PRECEDING
AND INTERVAL 3 DAYS FOLLOWING),
three AS (
PARTITION BY "Plant"
ORDER BY "Date" ASC
RANGE BETWEEN INTERVAL 1 DAYS PRECEDING
AND INTERVAL 1 DAYS FOLLOWING)
ORDER BY 1, 2;
上面的查询没有使用一些 SELECT 语句中常见的子句,如 WHERE、GROUP BY 等。对于更复杂的查询,你可以在 SELECT statement 的规范顺序中查看 WINDOW 子句的位置。
使用 QUALIFY 过滤窗口函数结果
窗口函数在 WHERE 与 HAVING 子句求值之后执行,因此不能用这两个子句过滤窗口函数结果。
QUALIFY 子句 可以避免为此再写子查询或 WITH 子句。
箱线图查询
所有聚合都可作为窗口函数使用,包括复杂统计函数。 这些函数实现已针对窗口计算进行优化, 我们可以用窗口语法编写查询来生成移动箱线图所需的数据:
SELECT "Plant", "Date",
min("MWh") OVER seven AS "MWh 7-day Moving Minimum",
quantile_cont("MWh", [0.25, 0.5, 0.75]) OVER seven
AS "MWh 7-day Moving IQR",
max("MWh") OVER seven AS "MWh 7-day Moving Maximum",
FROM "Generation History"
WINDOW seven AS (
PARTITION BY "Plant"
ORDER BY "Date" ASC
RANGE BETWEEN INTERVAL 3 DAYS PRECEDING
AND INTERVAL 3 DAYS FOLLOWING)
ORDER BY 1, 2;