Architecture
This section documents some design and implementation details.
SAX and DOM
The UML diagram below illustrates the basic relationship between SAX and DOM.
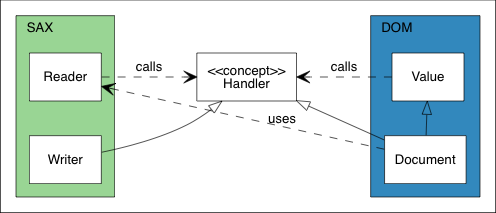
At the core of this relationship is the Handler concept. On the SAX side, the Reader parses JSON from a stream and sends events to a Handler. The Writer implements the Handler concept to process the same set of events. On the DOM side, the Document implements the Handler concept to construct the DOM from these events. The Value class provides the Value::Accept(Handler&) function, which converts the DOM into events and dispatches them.
In this design, SAX is independent of DOM. Even the Reader and Writer have no dependencies on each other. This provides flexibility in connecting event emitters and handlers. Additionally, Value is independent of SAX. Therefore, besides serializing the DOM to JSON, users can also serialize it to XML or perform any other operations.
Utility Classes
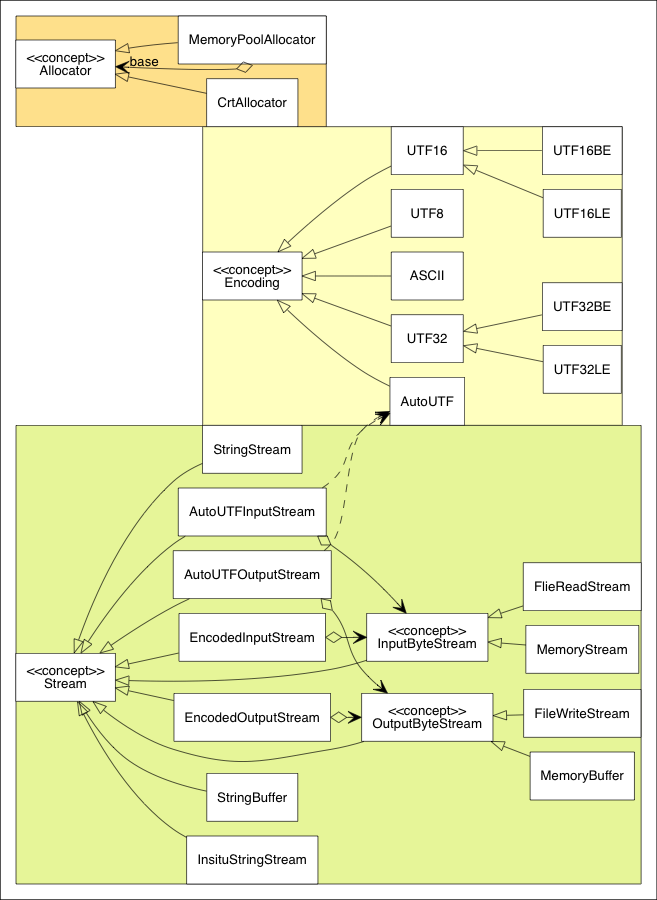
Both SAX and DOM APIs rely on three additional concepts: Allocator, Encoding, and Stream. Their inheritance hierarchy is shown in the diagram below.
Value
Value (actually defined as GenericValue<UTF8<>>) is the core of the DOM API. This section describes its design.
Data Layout
Value is a variant type. In the context of Merak, an instance of Value can hold one of six JSON data types. This is achieved using a union. Each Value contains two members: union Data data_ and unsigned flags_. The flags_ indicates the JSON type as well as additional information.
The table below shows the data layout for all types. The 32-bit/64-bit columns indicate the number of bytes occupied by each field.
| Null | Description | 32-bit | 64-bit |
|---|---|---|---|
| (Unused) | 4 | 8 | |
| (Unused) | 4 | 4 | |
| (Unused) | 4 | 4 | |
unsigned flags_ | kNullType kNullFlag | 4 | 4 |
| Bool | Description | 32-bit | 64-bit |
|---|---|---|---|
| (Unused) | 4 | 8 | |
| (Unused) | 4 | 4 | |
| (Unused) | 4 | 4 | |
unsigned flags_ | kBoolType (either kTrueFlag or kFalseFlag) | 4 | 4 |
| String | Description | 32-bit | 64-bit |
|---|---|---|---|
Ch* str | Pointer to string (may own ownership) | 4 | 8 |
SizeType length | String length | 4 | 4 |
| (Unused) | 4 | 4 | |
unsigned flags_ | kStringType kStringFlag ... | 4 | 4 |
| Object | Description | 32-bit | 64-bit |
|---|---|---|---|
Member* members | Pointer to member array (owns ownership) | 4 | 8 |
SizeType size | Number of members | 4 | 4 |
SizeType capacity | Member capacity | 4 | 4 |
unsigned flags_ | kObjectType kObjectFlag | 4 | 4 |
| Array | Description | 32-bit | 64-bit |
|---|---|---|---|
Value* values | Pointer to value array (owns ownership) | 4 | 8 |
SizeType size | Number of values | 4 | 4 |
SizeType capacity | Value capacity | 4 | 4 |
unsigned flags_ | kArrayType kArrayFlag | 4 | 4 |
| Number (Int) | Description | 32-bit | 64-bit |
|---|---|---|---|
int i | 32-bit signed integer | 4 | 4 |
| (Zero padding) | 0 | 4 | 4 |
| (Unused) | 4 | 8 | |
unsigned flags_ | kNumberType kNumberFlag kIntFlag kInt64Flag ... | 4 | 4 |
| Number (UInt) | Description | 32-bit | 64-bit |
|---|---|---|---|
unsigned u | 32-bit unsigned integer | 4 | 4 |
| (Zero padding) | 0 | 4 | 4 |
| (Unused) | 4 | 8 | |
unsigned flags_ | kNumberType kNumberFlag kUintFlag kUint64Flag ... | 4 | 4 |
| Number (Int64) | Description | 32-bit | 64-bit |
|---|---|---|---|
int64_t i64 | 64-bit signed integer | 8 | 8 |
| (Unused) | 4 | 8 | |
unsigned flags_ | kNumberType kNumberFlag kInt64Flag ... | 4 | 4 |
| Number (Uint64) | Description | 32-bit | 64-bit |
|---|---|---|---|
uint64_t i64 | 64-bit unsigned integer | 8 | 8 |
| (Unused) | 4 | 8 | |
unsigned flags_ | kNumberType kNumberFlag kInt64Flag ... | 4 | 4 |
| Number (Double) | Description | 32-bit | 64-bit |
|---|---|---|---|
uint64_t i64 | Double-precision floating-point number | 8 | 8 |
| (Unused) | 4 | 8 | |
unsigned flags_ | kNumberType kNumberFlag kDoubleFlag | 4 | 4 |
Some notes to consider:
- To reduce memory consumption on 64-bit architectures,
SizeTypeis defined asunsignedinstead ofsize_t. - The zero padding for 32-bit integers may be placed before or after the actual type, depending on endianness. This allows 32-bit integers to be interpreted as 64-bit integers without any conversion.
- An
Intis always anInt64, but the reverse is not true.
Flags
The 32-bit flags_ contains the JSON type and other information. As shown in the tables above, each JSON type includes redundant kXXXType and kXXXFlag flags. This design optimizes for testing bit flags (e.g., IsNumber()) and retrieving the sequence number of each type (e.g., GetType()).
Strings have two optional flags. kCopyFlag indicates that the string owns the copy of the string data. kInlineStrFlag means short string optimization is used.
Numbers are more complex. For regular integer values, flags_ may include kIntFlag, kUintFlag, kInt64Flag, and/or kUint64Flag, depending on the range of the integer. Numbers with fractional parts or integers exceeding the range of 64 bits are stored as double with the kDoubleFlag set.
Short String Optimization
Kosta contributed an excellent short string optimization. The principle of this optimization is described below. Excluding flags_, a Value has 12 or 16 bytes (for 32-bit or 64-bit architectures) to store actual data. This makes it possible to store short strings directly within the Value instead of storing a pointer to the string. For 1-byte character types (e.g., char), it can store strings of up to 11 or 15 characters inside the Value type.
| ShortString (Ch=char) | Description | 32-bit | 64-bit |
|---|---|---|---|
Ch str[MaxChars] | String buffer | 11 | 15 |
Ch invLength | MaxChars - Length | 1 | 1 |
unsigned flags_ | kStringType kStringFlag ... | 4 | 4 |
A special technique is used here: it stores (MaxChars - length) instead of the string length directly. This makes it possible to store 11 characters with a trailing \0.
This optimization reduces memory usage for string copies, improves cache coherence, and further boosts runtime performance.
Allocator
Allocator is a core concept in Merak:
concept Allocator {
static const bool kNeedFree; //!< Indicates whether this allocator requires calling Free().
// Allocates a memory block.
// \param size Size of the memory block in bytes.
// \returns Pointer to the allocated memory block.
void* Malloc(size_t size);
// Resizes a memory block.
// \param originalPtr Pointer to the current memory block. Null pointer is allowed.
// \param originalSize Current size of the memory block in bytes. (Design note: Some allocators may not track this, so passing it explicitly saves memory.)
// \param newSize New size of the memory block in bytes.
void* Realloc(void* originalPtr, size_t originalSize, size_t newSize);
// Frees a memory block.
// \param ptr Pointer to the memory block to free. Null pointer is allowed.
static void Free(void *ptr);
};
It is important to note that Malloc() and Realloc() are member functions, while Free() is a static member function.
MemoryPoolAllocator
MemoryPoolAllocator is the default memory allocator for the DOM. It only allocates memory and does not free it, making it ideal for building DOM trees.
Internally, it allocates memory blocks from an underlying allocator (default: CrtAllocator) and stores these blocks in a singly linked list. When a user requests memory allocation, it follows these steps:
- Use the user-provided buffer if available. (See User Buffer section in DOM)
- If the user-provided buffer is full, use the current memory block.
- If the current memory block is full, allocate a new memory block.
Parsing Optimization
Skip Whitespace with SIMD
When parsing JSON from a stream, the parser needs to skip four types of whitespace characters:
- Space (
U+0020) - Horizontal tab (
U+0009) - Line feed (
U+000A) - Carriage return (
U+000D)
This is a naive implementation:
void SkipWhitespace(InputStream& s) {
while (s.Peek() == ' ' || s.Peek() == '\n' || s.Peek() == '\r' || s.Peek() == '\t')
s.Take();
}
However, this requires four comparisons per character plus some branching, which has been identified as a performance hotspot.
To accelerate this process, Merak uses SIMD to compare 16 characters against the four whitespace characters in a single iteration. Currently, Merak supports SSE2, SSE4.2, and ARM Neon instructions. This optimization is only enabled for UTF-8 in-memory streams, including string streams or in situ parsing.
You can enable this optimization by defining RAPIDJSON_SSE2, RAPIDJSON_SSE42, or RAPIDJSON_NEON before including merak/json.h. Some compilers can detect these settings automatically, as shown in perftest.h:
// __SSE2__ and __SSE4_2__ are recognized by GCC, Clang, and Intel compilers:
// We use -march=native in gmake to enable -msse2 and -msse4.2 if supported
// Similarly, __ARM_NEON is used to detect Neon support
#if defined(__SSE4_2__)
# define RAPIDJSON_SSE42
#elif defined(__SSE2__)
# define RAPIDJSON_SSE2
#elif defined(__ARM_NEON)
# define RAPIDJSON_NEON
#endif
It is important to note that this is a compile-time setting. Running the executable on machines that do not support these instructions will cause a crash.
Page Alignment Issue
In early versions of Merak, a bug was reported: SkipWhitespace_SIMD() would rarely cause a crash (approximately 1 in 500,000 occurrences). After investigation, it was suspected that _mm_loadu_si128() accessed memory beyond '\0' and crossed a protected page boundary.
In the Intel® 64 and IA-32 Architectures Optimization Reference Manual, section 10.2.1 states:
To support algorithms that require unaligned 128-bit SIMD memory accesses, the caller’s memory buffer allocation should include padding so that the called function can safely use the address pointer for unaligned 128-bit SIMD memory operations. When combining unaligned SIMD memory operations, the minimum alignment size should be equal to the size of the SIMD register.
This is clearly not feasible for Merak, as Merak should not force users to align memory.
To fix this issue, the current code first processes bytes one by one until the next aligned address. After that, aligned reads are used for SIMD processing. See #85.
Local Stream Copy
During optimization, we found that some compilers fail to place accesses to stream member data into local variables or registers. Test results show that for some stream types, creating a copy of the stream and using it in inner loops improves performance. For example, the actual (non-SIMD) SkipWhitespace() is implemented as:
template<typename InputStream>
void SkipWhitespace(InputStream& is) {
internal::StreamLocalCopy<InputStream> copy(is);
InputStream& s(copy.s);
while (s.Peek() == ' ' || s.Peek() == '\n' || s.Peek() == '\r' || s.Peek() == '\t')
s.Take();
}
Based on the characteristics of the stream, StreamLocalCopy creates (or does not create) a copy of the stream object, uses it locally, and copies the stream state back to the original stream.
Parsing to Double-Precision Floating-Point
Parsing a string to a double is non-trivial. The standard library function strtod() can do this, but it is relatively slow. By default, the parser uses normal precision settings, which have a maximum error of 3 ULP and are implemented in internal::StrtodNormalPrecision().
When the kParseFullPrecisionFlag is used, the parser instead calls internal::StrtodFullPrecision(), which automatically invokes three versions of conversion:
- Fast-Path.
- A custom DIY-FP implementation from double-conversion.
- A big-integer algorithm from (Clinger, William D. How to read floating point numbers accurately. Vol. 25. No. 6. ACM, 1990).
If the first conversion method fails, it tries the second, and so on.
Generation Optimization
Integer to String Conversion
The naive algorithm for integer-to-string conversion requires one division per decimal digit. We implemented several versions and evaluated them in itoa-benchmark.
Although the SSE2 version is the fastest, it has only a small performance gap with the second-fastest branchlut version. Additionally, branchlut is a pure C++ implementation, so we use branchlut in Merak.
Double-Precision Floating-Point to String Conversion
Originally, Merak used snprintf(..., ..., "%g") for double-to-string conversion. This is inaccurate because the default precision is 6. Later, we found it to be slow and identified alternative approaches.
Google’s V8 double-conversion library implements a newer, fast algorithm called Grisu3 (Loitsch, Florian. "Printing floating-point numbers quickly and accurately with integers." ACM Sigplan Notices 45.6 (2010): 233-243.).
However, this implementation is not header-only, so we implemented a header-only version of Grisu2. This algorithm guarantees that the result is always precise and, in most cases, generates the shortest possible (canonical) string representation.
This header-only conversion function is evaluated in dtoa-benchmark.
Parser
Iterative Parsing
The iterative parser is a non-recursive implementation of a recursive-descent LL(1) parser.
Grammar
The grammar used by the parser is based on the strict JSON grammar:
S -> array | object
array -> [ values ]
object -> { members }
values -> non-empty-values | ε
non-empty-values -> value addition-values
addition-values -> ε | , non-empty-values
members -> non-empty-members | ε
non-empty-members -> member addition-members
addition-members -> ε | , non-empty-members
member -> STRING : value
value -> STRING | NUMBER | NULL | BOOLEAN | object | array
Note that left factoring is applied to the values and members non-terminals to ensure the grammar is LL(1).
Parsing Table
Based on this grammar, we can construct the FIRST and FOLLOW sets.
The FIRST sets for non-terminals are shown below:
| Non-terminal | FIRST |
|---|---|
| array | [ |
| object | { |
| values | ε STRING NUMBER NULL BOOLEAN { [ |
| addition-values | ε COMMA |
| members | ε STRING |
| addition-members | ε COMMA |
| member | STRING |
| value | STRING NUMBER NULL BOOLEAN { [ |
| S | [ { |
| non-empty-members | STRING |
| non-empty-values | STRING NUMBER NULL BOOLEAN { [ |
The FOLLOW sets for non-terminals are shown below:
| Non-terminal | FOLLOW |
|---|---|
| S | $ |
| array | , $ } ] |
| object | , $ } ] |
| values | ] |
| non-empty-values | ] |
| addition-values | ] |
| members | } |
| non-empty-members | } |
| addition-members | } |
| member | , } |
| value | , } ] |
A parsing table can be generated from the FIRST and FOLLOW sets as follows:
| Non-terminal | [ | { | , | : | ] | } | STRING | NUMBER | NULL | BOOLEAN |
|---|---|---|---|---|---|---|---|---|---|---|
| S | array | object | ||||||||
| array | [ values ] | |||||||||
| object | { members } | |||||||||
| values | non-empty-values | non-empty-values | ε | non-empty-values | non-empty-values | non-empty-values | non-empty-values | |||
| non-empty-values | value addition-values | value addition-values | value addition-values | value addition-values | value addition-values | value addition-values | ||||
| addition-values | , non-empty-values | ε | ||||||||
| members | ε | non-empty-members | ||||||||
| non-empty-members | member addition-members | |||||||||
| addition-members | , non-empty-members | ε | ||||||||
| member | STRING : value | |||||||||
| value | array | object | STRING | NUMBER | NULL | BOOLEAN |
For the grammar analysis above, there is an excellent tool available.
Implementation
Based on this parsing table, a straightforward (conventional) implementation that pushes rules onto the stack in reverse order works correctly.
In Merak, several modifications are made to the straightforward implementation:
First, in Merak, the parsing table is encoded as a state machine. Rules consist of a head and a body, and state transitions are constructed from the rules. Additionally, extra states are added to rules related to array and object. This allows generating array values or object members with a single state transition, instead of multiple stack push/pop operations in the straightforward implementation. It also makes it easier to estimate the stack size.
The state diagram is shown below:
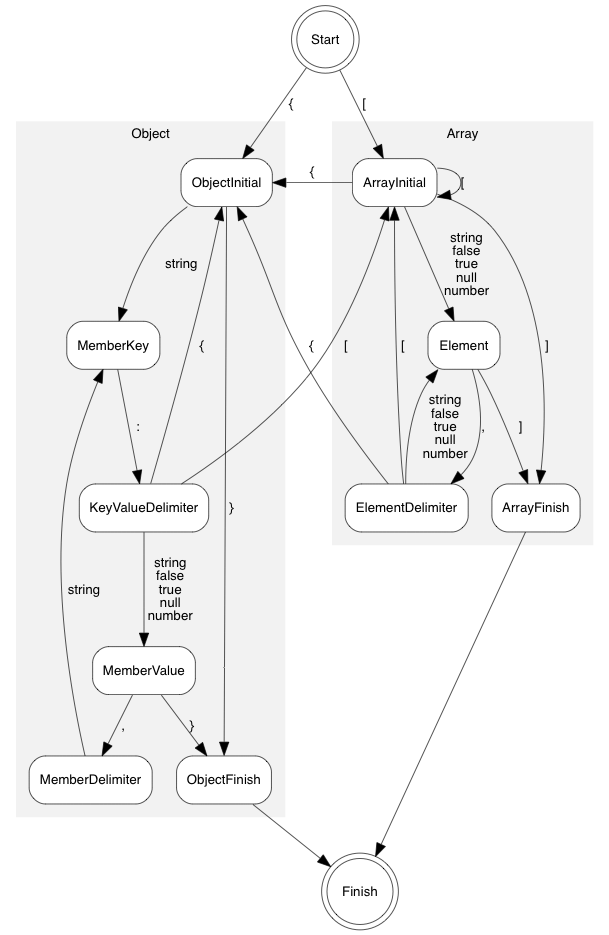
Second, unlike traditional implementations, the iterative parser also stores the number of array values and object members in its internal stack.